SQL Server Management Studio (SSMS) を使って、 SQL Server を操作しているのですが、 SSMS ってそのままクエリを書くと Shift-JIS で保存されます。
で、いろいろあって、このクエリを Unicode (utf-8) に変換して管理しています。
ここで、 utf-8 への変換に nkf を使っていたのですが、全角マイナスが入っていると妙な文字に変換されることに気が付きました (なお、 iconv だと変換元のファイルの文字コードを指定する必要があって、それを避けたかったので、 nkf を使っています)。
このトラブルについて調べたので、せっかくなのでメモにしておきます。
なお、作業環境としては基本的に Windows 10 ですが、コマンドライン操作は wsl2 (Ubuntu 20.04) で行っています。
トラブルについて
例えば、全角マイナス1文字だけの Shift-JIS のファイルを用意して
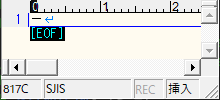
mor@DESKTOP-DE7IL4F:~/tmp/jm$ xxd sample_zen_minus_sjis.txt 00000000: 817c 0d0a .|.. mor@DESKTOP-DE7IL4F:~/tmp/jm$
nkf を使って変換します。
mor@DESKTOP-DE7IL4F:~/tmp/jm$ nkf -w sample_zen_minus_sjis.txt > sample_zen_minus_utf8_w.txt
中身を見てみると

mor@DESKTOP-DE7IL4F:~/tmp/jm$ xxd sample_zen_minus_utf8_w.txt 00000000: e288 920d 0a ..... mor@DESKTOP-DE7IL4F:~/tmp/jm$
となります。微妙に半角マイナスっぽい感じになってますね(Unicode 表記だと U+2212 なので半角マイナスとは違いますね)。
検証のために、テキストエディタ(サクラエディタ)で、全角マイナスを入力してutf-8で保存すると、

mor@DESKTOP-DE7IL4F:~/tmp/jm$ xxd sample_zen_minus_utf8_editor.txt 00000000: efbc 8d0d 0a ..... mor@DESKTOP-DE7IL4F:~/tmp/jm$
となり、 Unicode 表記で U+FF0D となるので、先ほどの nkf による変換後のファイルの中身が全角マイナスとは違っていることがわかります。
さて、これはどういうことなんでしょうか?
原因と解決方法
これ、全然知らなかったのですが、下記の記事で書かれているように、有名な問題だったようです。
UTF-8における全角マイナスと全角チルダの問題(=いわゆる「波ダッシュ問題」) - 半径5メートル
この記事内からも参照されていますが、Wikipedia にも記載があります。
Wikipedia のほうには文字コードも載っているので、それと合わせると上記の変換結果と対応することがわかります。
結局、原因としては、仕様、ということのようです。
まあ、仕様なのはしょうがないのですが、一緒に解決法も載っていました(ありがたいです)。
nkf の場合は -w ではなく --ic と --oc を使って入力の文字コードを指定すればよいそうです。 なるほど。 Wikipedia の説明を踏まえると、 nkf の場合、 Shift-JIS から Unicode へ変換するのと CP932 から Unicode へ変換するので、変換先が違うんですね。
試してみます。
mor@DESKTOP-DE7IL4F:~/tmp/jm$ nkf --ic=cp932 --oc=utf8 sample_zen_minus_sjis.txt > sample_zen_minus_utf8_icoc.txt
ダンプしてみると
mor@DESKTOP-DE7IL4F:~/tmp/jm$ xxd sample_zen_minus_utf8_icoc.txt 00000000: efbc 8d0d 0a ..... mor@DESKTOP-DE7IL4F:~/tmp/jm$
おお、さっき、テキストエディタで保存した場合と一致しましたね。問題ないです。
ちなみに、iconv の場合も試しましたが、
mor@DESKTOP-DE7IL4F:~/tmp/jm$ iconv -f sjis -t utf8 sample_zen_minus_sjis.txt > sample_zen_minus_utf8_iconv.txt mor@DESKTOP-DE7IL4F:~/tmp/jm$ xxd sample_zen_minus_utf8_iconv.txt 00000000: e288 920d 0a ..... mor@DESKTOP-DE7IL4F:~/tmp/jm$ mor@DESKTOP-DE7IL4F:~/tmp/jm$ iconv -f cp932 -t utf8 sample_zen_minus_sjis.txt > sample_zen_minus_utf8_iconv_cp932.txt mor@DESKTOP-DE7IL4F:~/tmp/jm$ xxd sample_zen_minus_utf8_iconv_cp932.txt 00000000: efbc 8d0d 0a ..... mor@DESKTOP-DE7IL4F:~/tmp/jm$
となるように、入力ファイルの文字コードを sjis と指定すると nkf と同じ問題が起きますね(解決法も同じ)。
にしても、こんな問題があるなんて、やっぱり文字コードは怖いですね。