いままでは、 GAS (Javascript)でスクレイピングしてたんですが、どうも対象サイトの仕様が変わってしまって、動的ページになったため GAS ではうまく取得できなくなりました。
で、せっかくの機会なので、 Python で動的ページのスクレイピングをやってみましたので、自分用にあれこれメモっておきます。
Python 3.13.1, venv 環境で利用
開発環境は Windows 11 上の WSL (Ubuntu 24.04.1) を VSCode からリモートで接続したものを使いました。
ローカルで実装
まずは、こちらのサイトの記事などを参考にして Python でスクレイピングするのに、必要なパッケージである
- selenium
- webdriver manager
をインストールしておきます。
(.venv)mor@DESKTOP-DE7IL4F:~/tmp/scraping/dynamic$ pip install selenium (.venv)mor@DESKTOP-DE7IL4F:~/tmp/scraping/dynamic$ pip install webdriver_manager
selenium は 4.27.1 でした。
早速、こちらの記事などを参考に試してみると、

あれ?
エラーになってますね。調べてみると、
[Python] seleniumの仕様が変わっていた!?(2023/06時点)
Selenium の仕様が変わったようです。なので、こちらにも載ってる新しい記述に変更します。
まずは、webdriver manager をアンインストールしておきます。
(.venv) mor@DESKTOP-DE7IL4F:~/tmp/scraping/dynamic$ pip uninstall webdriver-manager Found existing installation: webdriver-manager 4.0.2 Uninstalling webdriver-manager-4.0.2: Would remove: /home/mor/tmp/scraping/dynamic/.venv/lib/python3.13/site-packages/webdriver_manager-4.0.2.dist-info/* /home/mor/tmp/scraping/dynamic/.venv/lib/python3.13/site-packages/webdriver_manager/* Proceed (Y/n)? y Successfully uninstalled webdriver-manager-4.0.2 (.venv) mor@DESKTOP-DE7IL4F:~/tmp/scraping/dynamic$
コードは
from selenium import webdriver driver = webdriver.Chrome() driver.get("https://www.google.com") print(driver.title)
こんな感じにします。
で、実行すると
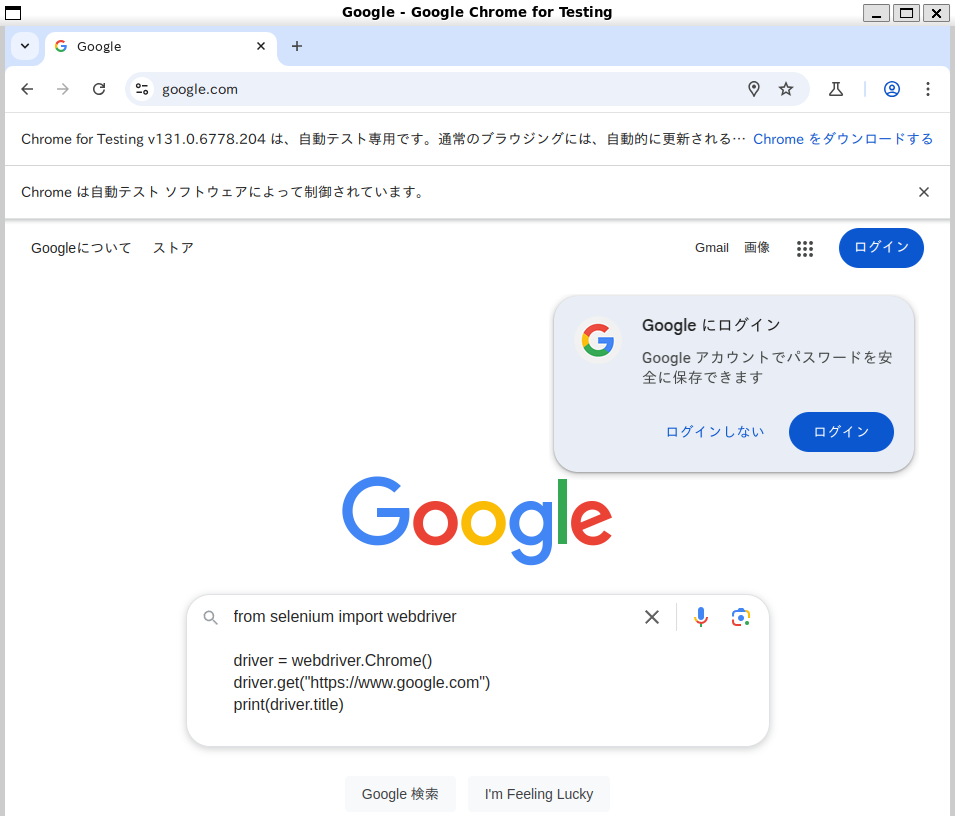
おぉ、ブラウザが立ち上がりますね。コンソールにも

print でページタイトルが出てますね。
にしても、 WSL って特に設定しなくても、 X サーバーの機能提供してくれてるんですっぽいですね。 WSLg というのが X サーバーの役割も提供しているそうです。そういや以前 X サーバーが不要になったような話を聞いたような聞いてないような記憶が・・・あいまいですいません。
改めて調べてみると、ずばり書いてありました。
- Windows11ではWSL2のGUI表示にXサーバー使わなくていいってほんまか!? #ポエム - Qiita
- WSL2の新機能WSLgを使ってX Window SystemのGUIアプリを動作させてみる - uepon日々の備忘録
便利になったもんだ。手元の環境のバージョンを表示させてみると、
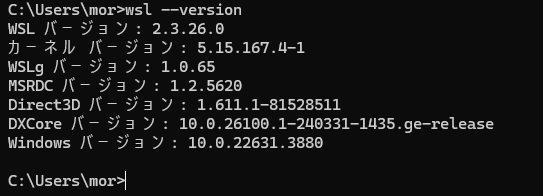
WSLg の表記があるので有効になっていたようです。
あと、 WSL (Ubuntu) に Chrome もインストールしてないのに、ちゃんと起動するんですね。これも、気になったので調べてみると、 Selenium 4.11 からの機能のようです。
Selenium 4.6はドライバ、4.11ではブラウザすら準備してくれる - ガンマソフト
この記事にあるように、 chrome 本体がダウンロードされているはずなので、それを見てみると、
(.venv) mor@DESKTOP-DE7IL4F:~/.cache/selenium$ ls -l 合計 12 drwxr-xr-x 3 mor mor 4096 12月 20 17:28 chrome drwxr-xr-x 3 mor mor 4096 12月 20 17:28 chromedriver -rw-r--r-- 1 mor mor 576 12月 20 21:44 se-metadata.json (.venv) mor@DESKTOP-DE7IL4F:~/.cache/selenium$
~/.cache/selenium 以下にありました。なるほどね。
要素を取得
こちらのサンプルにあったように Yahoo!ニュースから記事のタイトル一覧を取得してみます。find_elements_by_css_selector は find_element に変わっているようなので、その点だけ書き換えておきます。
from selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome() driver.get("https://news.yahoo.co.jp") print(driver.title) headlines = driver.find_elements(By.CSS_SELECTOR, "#uamods-topics > div > div > div > ul a") for headline in headlines: print(headline.text) #driver.quit()
で実行すると、
この画面に対して、
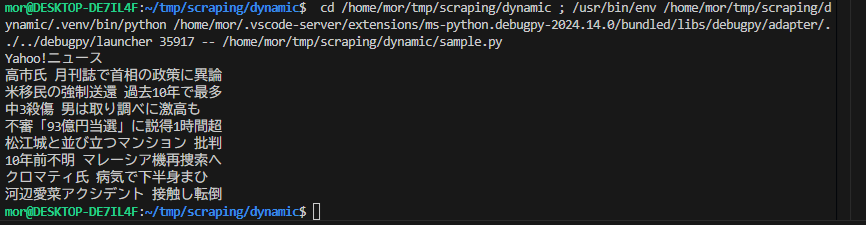
のように記事のタイトルが取得できてますね。
これで、あとは対象となるサイトに応じて処理を記述すればよさそうです。
ページ遷移と表示待ち
スクレイピングをやるとなると、ボタンをクリックして次のページへ移動する、なんてことがよくあると思います。こういう時の待機はどうするんだろうか?と思って調べてみると、下記のような形でできるっぽいです。
【初心者向け】PythonのseleniumでChrome自動操作する時に使うビジーウェイトは大抵これで解決! | ゆとり院卒Life
待機のパターンもいろいろと用意されています。
- Seleniumで待機処理するお話 #Python - Qiita
- Selenium for Python 要素の状態変化のための待機と取得に関して統一的な方法を模索する #Python - Qiita
- 【Selenium × Python】excepted_conditionsの条件を整理した #テスト自動化 - Qiita
とりあえず、指定した要素が読み込まれるまで待機する、というのを実装してみると
def waitForPage(driver): """ ページ読み込みの待機 """ try: WebDriverWait(driver, WAIT_TIME).until( EC.presence_of_element_located((By.ID, "そのページに存在してほしい要素の ID")) ) except TimeoutException as te: print(f"ページ遷移でタイムアウトしました: {te}") driver.quit() exit() return
これをボタンクリック後などで呼び出せば、ちゃんと待機してくれてました。
ヘッドレスモードで動かす
手元の VSCode で試している分にはこれで十分なんですが、先々は Lambda で動かすようにしたいと思います。ということで、ヘッドレスモードを試します。
【selenium】headless備忘録 #Python - Qiita
オプションを指定するだけでいいんですね。やってみます。
# webdriverの設定 options = webdriver.ChromeOptions() options.add_argument("--headless") options.add_argument("--disable-gpu") driver = webdriver.Chrome(options=options) driver.get(TARGET_URL)
今度はブラウザが表示されずに、処理が動きました。いやー、簡単ですね。
メール送信
スクレイピングしたら、その結果を受け取りたいと思います。Python だとメールの送信も簡単にできそうです。
こちらの記事のほうが詳しいですが、ここにも一応流れを書いておきます。
まず、メールで送りたいメッセージを MIME 形式のメッセージとして作ります。引数に、件名とメール本文をとる関数にしておきます。メッセージはテキスト形式にします。
def create_mime_message(subject, message): """ MIME 形式のメッセージを作成 """ from email.mime.text import MIMEText from email.utils import formatdate msg = MIMEText(message, "plain", "utf-8") msg["Subject"] = subject msg["From"] = "送信元メールアドレス" msg["To"] = "送信先メールアドレス" msg["Date"] = formatdate() return msg
メールを送るときは、次の関数を呼び出すようにします。SMTP サーバーはさくらインターネットのサーバーで、 SMTPS (ポート 465 )を使うことを想定しています。
def send_email(subject, message): """ メール送信 """ import smtplib import ssl mime = create_mime_message(subject, message) print(f"mime") account = "IMAPのアカウント" password = "パスワード" host = "SMTP サーバー" port = 465 context = ssl.create_default_context() server = smtplib.SMTP_SSL(host, port, context=context) server.login(account, password) server.send_message(mime) server.quit()
適当な件名とメッセージ本文を与えて、この関数を呼び出すと、問題なくメールが送信できました。 Python ベンリー。
まとめ
Python でスクレイピングして必要な情報をとって、メールを送信するところまで試しました。めっちゃ簡単にできますね。次は、これを Lambda で動かしてみたいと思います。
おまけ
上記の記事の作業ですが、一日でやったのではなく、何日かに分けて試していました。
そのある日、 VSCode 上でデバッグ実行しても、ブラウザが起動せずにデバッグが完了しない事態になりました。
何度か試しても同じだったのですが、しばらくほっておいたら、
driver = webdriver.Chrome()
のところで、 NoSuchDriverException という例外が出て止まってしまいました。
理由はわかりませんが、どうも selenium が使う chrome driver が正しく認識されない状態になったようです。でも、 selenium インストール後、特に環境も変更していないのに不思議です。あと、 Python インタープリターは venv 環境のものを指定していました。
いろいろと試しても修正方法がわからなかったので、 venv 環境で pip install selenium を再度実行してから、もう一度 VScode からデバッグしたら、問題なくうまく実行できました。なお、 pip install の際は、
(.venv) mor@DESKTOP-DE7IL4F:~/tmp/scraping/dynamic$ pip install selenium Requirement already satisfied: selenium in ./.venv/lib/python3.13/site-packages (4.27.1) 略
のような感じで、既にあるよ的になメッセージがずらずらと表示されいました。何か修正されたんだろうか?
まあ、謎っちゃ謎ですが、こんなこともあったとので、一応メモっておきます。