以前から、やろうやろうと思っていましたが、のびのびになっていた、 QNAP のクラウドバックアップですが、 Hybrid Backup Sync 3 (以下、 HBS3 と略します)を使うと簡単にできそうだったので、試してみましたので、いろいろとメモっておきます。
ちなみに、参考にした元ネタは下記の記事になります。
【家庭用NAS】QNAP TS-131でファイルを自動的にS3へリモートバックアップする | Developers.IO
- 背景
- S3 の設定
- QNAP 上のクラウドストレージ領域の作成
- バックアップジョブの作成
- バックアップジョブからの復元
- バックアップジョブの設定内容とS3での状態
- QuDedup Extract Tool による復元
- バックアップジョブの削除
- まとめ
背景
現状、2台の NAS 間でデータフォルダの同期をさせていて、一応メインの NAS が壊れても、すぐにもう一台を使って作業を継続できる体制にしていますが、これだと、仕事場が浸水するとかしてしまうとすべてのデータがなくなる可能性があります(最近は、局地的な豪雨とかもひどいものがありますからね)。 ということで、データのバックアップをクラウド上に置いたいとかねてから思っていました( NAS を選ぶときに QNAP を選択した理由の一つでもあります)。
でも、今の今まで設定を先延ばしにしていました。
先日、 NAS 間のデータ転送でちょっと不可解な動きがあったので、問題が起きる前に改めてクラウドバックアップをやっておこうと思った次第です。
バックアップ先のクラウドとしては、何を使おうか若干迷ったのですが、ここは毎度おなじみの S3 を使うことにしました。
S3 の設定
QNAP 上でバックアップジョブの設定時に新規作成することもできるようですが、まず、 AWS のコンソール(もちろん、CLI でもなんでもOKです)から保存先となる S3 のバケットを作成しておきます。
今回作成したバケットは
- バージョニング:なし
- 暗号化:なし
- ライフサイクルルール:指定なし
というシンプルなものです。当然非公開のバケットです。
QNAP 上のクラウドストレージ領域の作成
次に、作成したバケットを QNAP 上にクラウドストレージとして登録します。
QNAP のコンソールにログインして、 HBS3 を起動します。
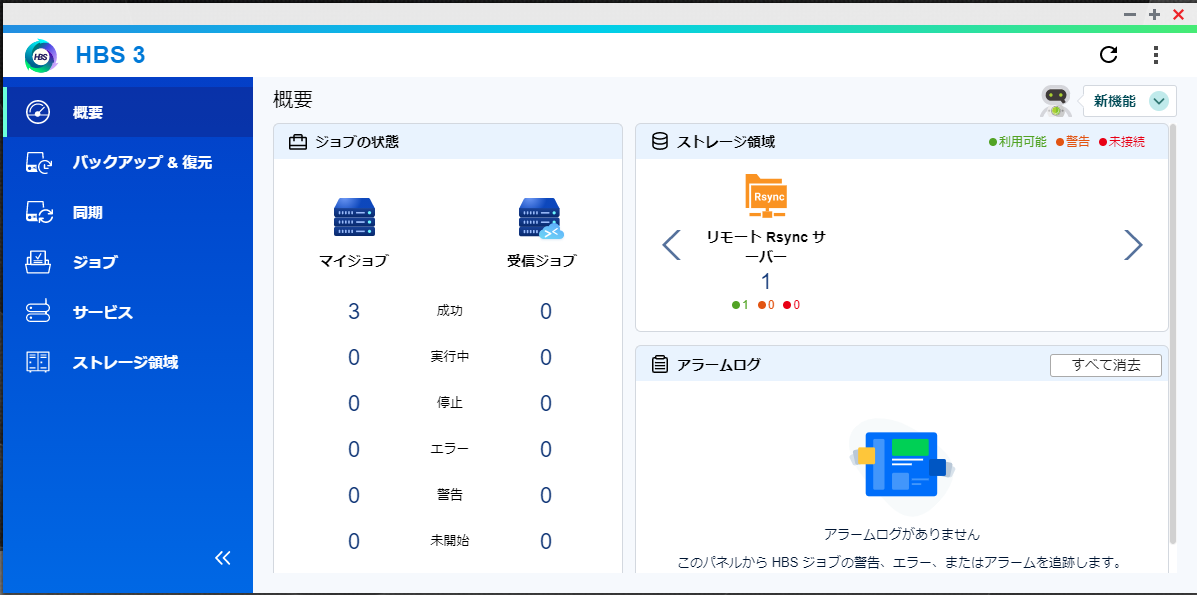
左側のメニューより『ストレージ領域』を選択し、『作成』を選びます。

すると、クラウドストレージの一覧が表示されるので、自分が使いたいサービスのものを選択します(今回ですと S3 )。 サービスごとに設定画面が表示されるので、必要な設定を入力していきます。S3の場合は、下記にあるように、アクセスキーとシークレットアクセスキーを設定します。
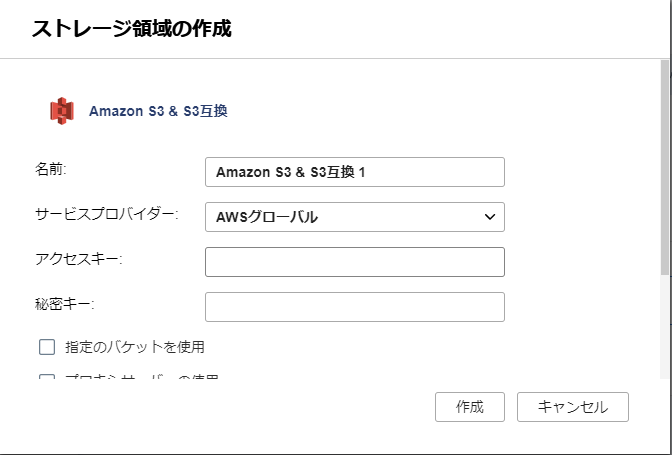
なお、アクセスキーは、S3FullAccess の権限を持った IAM ユーザーのものになりますので、当該ユーザーがなければ、AWSのコンソールにてIAMユーザーを作成してください。
今回は、S3のアクセス権限を特定のバケットに制限する管理ポリシーについての記事を参考に、ポリシーを作成し、新しいIAMユーザーに割り当て、そのユーザーのアクセスキーとシークレットアクセスキーを用いました。
あと、バケット名としてさきほど作成したバケットを指定すれば完了です。
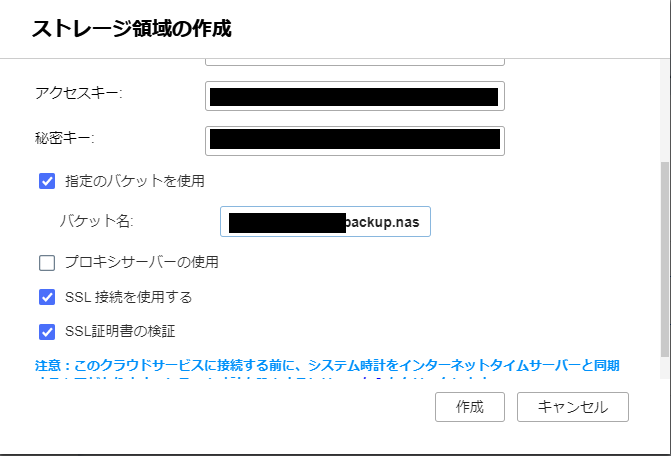
作成後はこんな感じになりました。

バックアップジョブの作成
クラウドストレージ領域を設定したので、次はバックアップジョブを作成します。
なお、HBS3はいろいろと機能があるので、バックアップジョブを作成する前に、こちらの紹介記事などに一通り目を通しておくと、こんなことができて、そのための設定項目なんだなと全体像がつかみやすくなるかと思います。
『バックアップ&復元』を選択し、
『新しいバックアップジョブ』を選択します。
バックアップの対象および保存先を設定
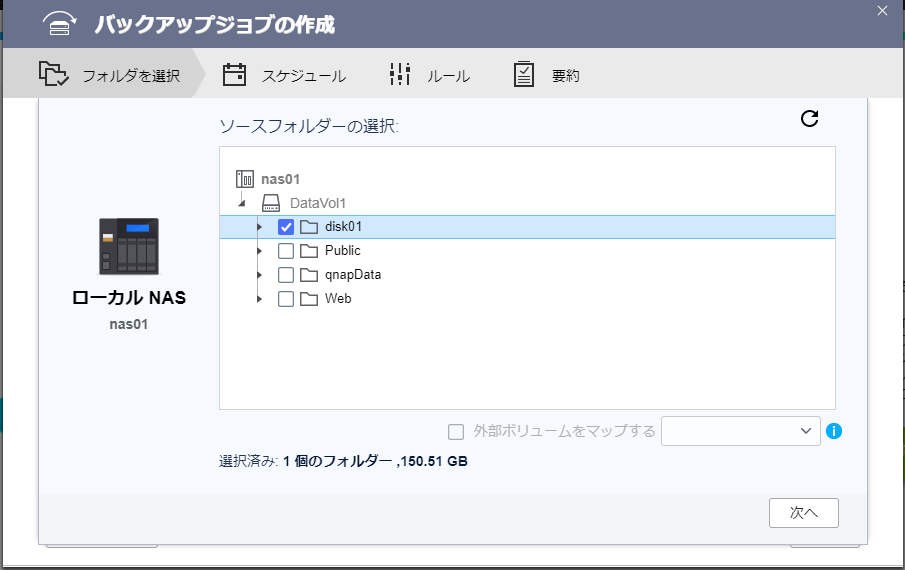
まずは、バックアップの対象となるローカルフォルダを指定します。
次に、バックアップ先を選択します。ここでは、S3 上に保存したいので、S3を選択します。S3 を選択するとさきほど作成したクラウドストレージが表示されるのでそれを選択します。

ストレージクラス、暗号化など、必要な設定を行います。
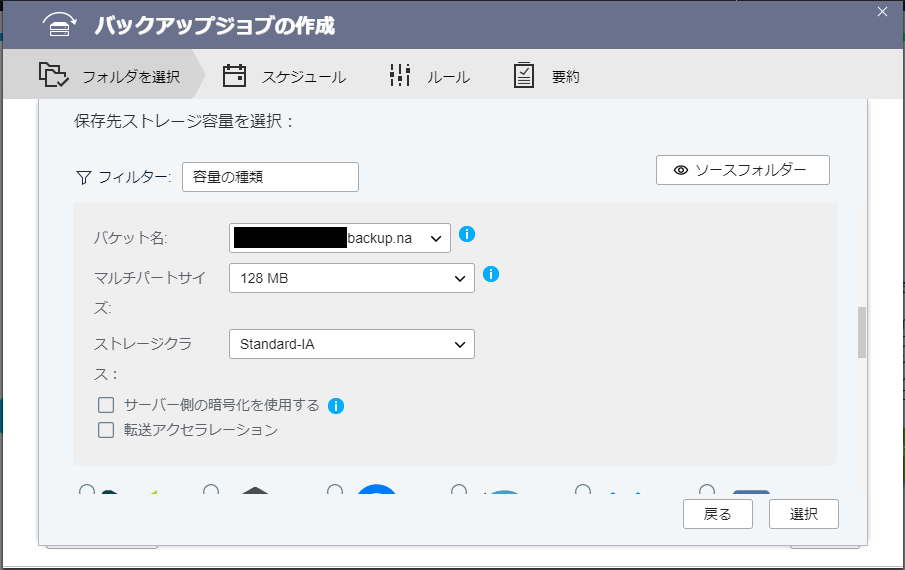
ただし、いろいろと設定を試した際の印象では『サーバー側の暗号化を使用する』のオプションを設定しても、バケット側の設定で暗号化が無効であれば、有効には切り替わらないように思えます(このあたり、正確な情報が見つけられませんでした)。
次に、必要があれば、保存先になる S3 上のフォルダを指定します。特になければ、バケットのルートで問題ないです。
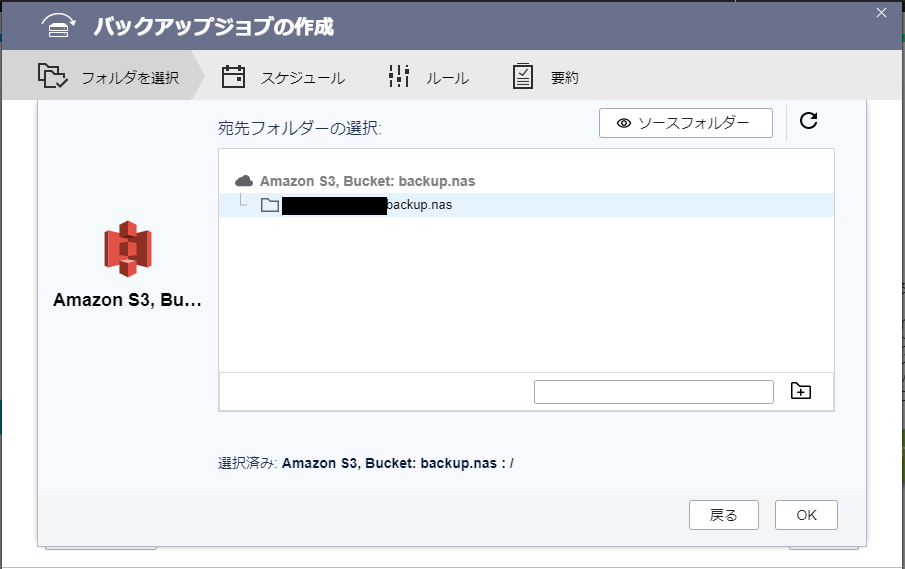
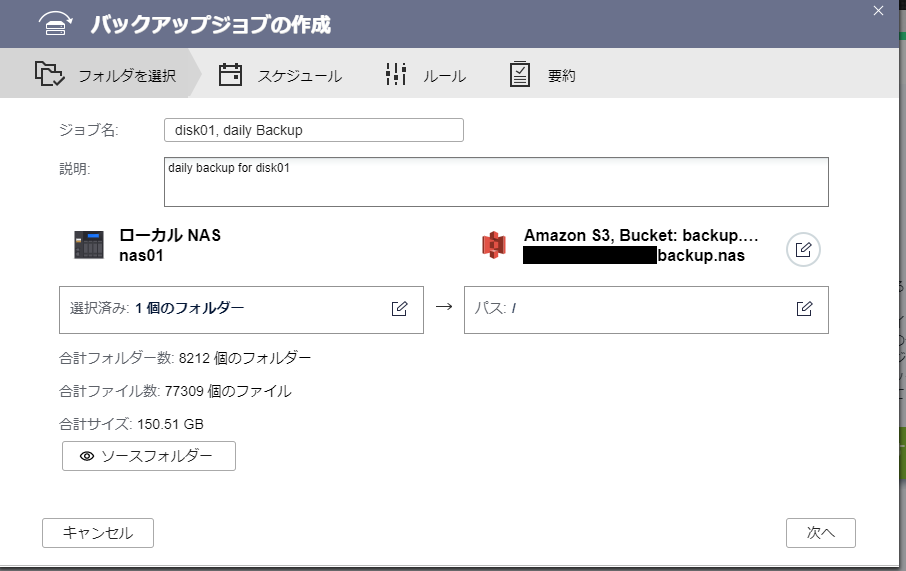
ジョブ名を聞かれるので入力します。実はこのジョブ名を用いたフォルダが、先ほど指定した保存先フォルダ内に作成され、その内部にバックアップが作成されます。
スケジュールおよびその他の設定
次にジョブのスケジュールを設定します。スケジュールを設定せずにジョブだけ作成し、HBS3のコンソールから手動で実行することもできます。
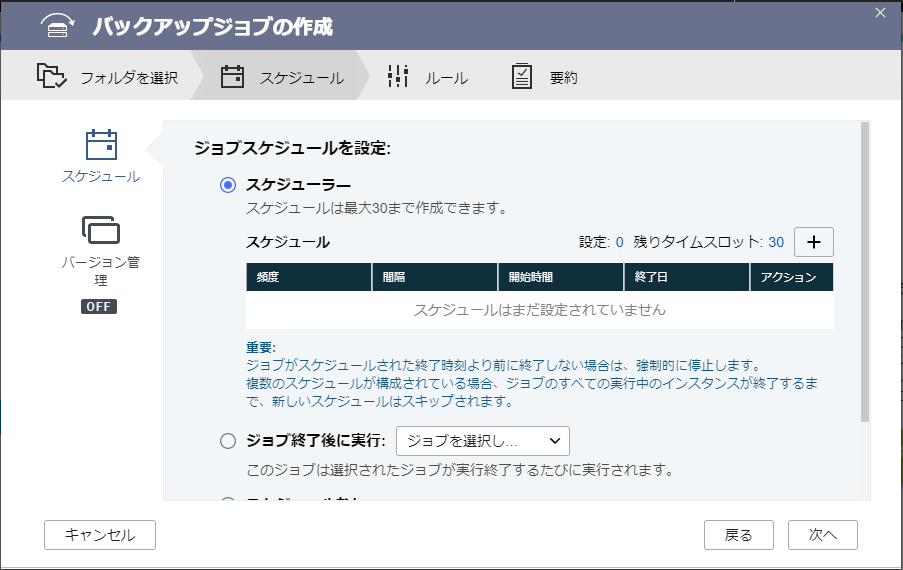
画面下部にある『今すぐバックアップ』にチェックを入れておくと、ジョブ作成が完了したらすぐにバックアップがおこなわれます。

併せて、バージョン管理もここで指定します。
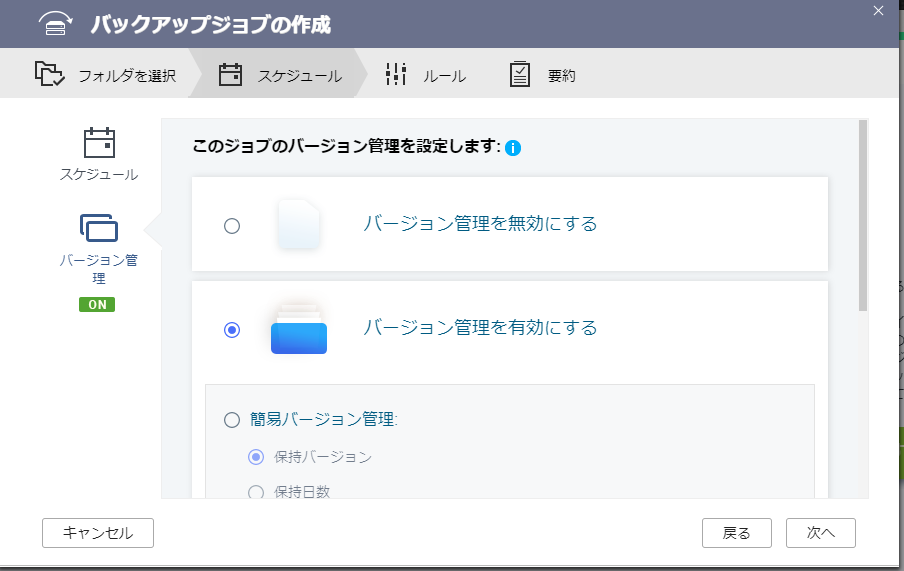
バージョン管理は、
- 簡易バージョン管理
- スマートバージョニング
の2種類から選択できます。前者の管理バージョン管理は、バックアップ数またはバックアップ日数による管理になります。スマートバージョニングは、日次、週次、月次のバックアップを何世代残す、というよくあるタイプの設定ができます(今回はスマートバージョニングにしました)。
次にバックアップ対象のフィルタリングなどを指定します(今回は試していません)。

この際、 QuDedup という機能を利用するか否かを指定します。
これは QNAP が提供するバックアップの効率化のための機能のようです。とはいえ、 QNAP が提供する機能なので、これを利用するということはバックアップファイルの復元時に、原則として QNAP の NAS が必要になることを意味します。なので、これを用いるかどうかは、バックアップしたデータをどのように復元したいかに応じて決めることになると思います(詳しくは後述します)。
もっとも、通常は QNAP の NAS 上から復元も行うと思いますので、デフォルトのままで問題ないかと思います(今回はデフォルトのQuDedup を利用する にしました)。
ここまで設定が完了すると、最後に要約が表示されます。
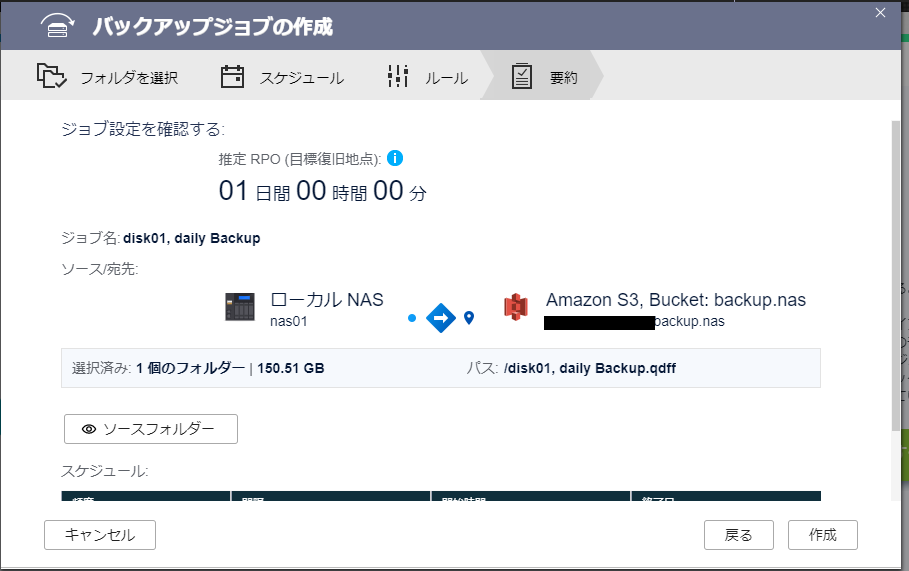
問題なければ、『作成』ボタンを押すとバックアップジョブが作成されます。
バックアップ開始
実際にジョブがスタートすると、QNAP の HBS3 上ではこのような感じで進捗状況を見ることができます。

S3 上の状態
さて、上記で作成したバックアップの完了後、 S3 上ではどのように保存されているかを確認してみました。
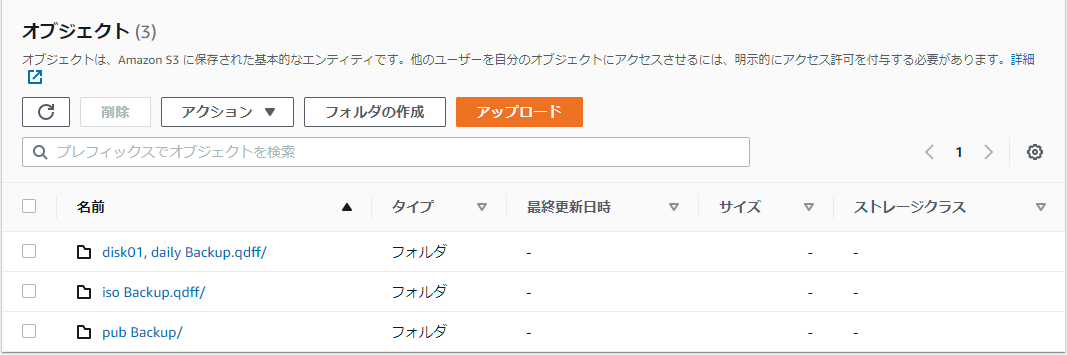
今回のバックアップジョブ名のついたフォルダ(disk01, daily Backup.qdff/)があるので、中を見てみると

こんな感じです。どんどんフォルダを掘り下げていっても、なじみのあるローカルフォルダにあったファイルは出てきません。単に、ローカルストレージのファイルがそのままS3上のオブジェクトになっているのかと思いきや、バックアップツール(今回の場合は QuDedup 機能が該当すると思います)が専用の形式にして保存しているようです。S3 は純粋なストレージ領域という扱いですね。
やはり前述したように、S3 上で直接ファイルを見ることはできないので復元には QNAP が必要になるということが、ここからもわかりますね。
バックアップができたので、次は復元も試しておきます。
バックアップジョブからの復元
復元も QNAP 上の HBS3 で行います。
HBS3 を開いて『バックアップ&復元』を選択肢、『作成』から『復元ジョブ』を選択します。
復元元のストレージとして『S3』を選択します。

『ソース』として『バックアップジョブ』を選択すると、下記のように複数のバックアップジョブから選択することができるようになります。ジョブを選択すると、自動的に関連する設定が有効になるそうです。

なお、『宛先』とあるのは日本語訳の問題のようで、ヘルプを表示させると

『ターゲットから復元』の意味だと思われます(『ターゲット』を『宛先』としたんでしょうね)。
バックアップジョブを選択すると、『ソースの選択』欄が表示されるので、

クリックすると、復元したいバックアップおよびフォルダを選択する画面になります。バージョン管理が有効な場合はどの過去バージョンを利用して復元するかも選択できます。

もし、バージョン管理がオフ(かつQuDedup無効)の場合はフォルダのみの選択ダイアログになります。
最後に、復元先を指定します。
あとはスケジュールで指定したタイミングで復元するか、スケジュール指定を行わずに手動で復元させるかを決めます。今回はスケジュールは指定しないが『今すぐ復元』にチェックをつけて、ジョブを作成後すぐさま復元を行うようにしました。
『ルール』では、復元時の各種設定を行うことができます(今回はデフォルトとしました)。
設定が終わったら、最後に要約画面が表示されるので、『復元』を押すと復元ジョブが作成されます。もし、『今すぐ復元』にチェックがついていれば続いて復元が実行されます。

復元中は下記のような感じでした。

復元ジョブが完了して、指定したフォルダを見ると、問題なくファイルが作成されていました。
バックアップジョブの設定内容とS3での状態
さて、バックアップジョブですが、いろいろと試してみると、
- QuDedup 利用の有無
- バージョン管理の有無
により、S3 上のオブジェクトの作成状況が変わるようです。
具体的には、
| QuDeDup の利用 | バージョン管理 | S3での保存のされ方 |
|---|---|---|
| あり | あり | qdff フォルダ内に専用のファイル形式 |
| あり | なし | qdff フォルダ内に専用のファイル形式 |
| なし | あり | qdff フォルダ内に専用のファイル形式 |
| なし | なし | ローカル構成に基づいたフォルダおよびオブジェクト構成 + 管理オブジェクト |
という感じでした。
qdff フォルダを利用している場合は、前述したようにローカルファイル単位でS3のオブジェクトが作られるのではなく、バックアップツールが独自の形式でローカルフォルダの内容を保存しているようです。このため、復元には QNAP もしくは後述する専用ツールが必要になります。
一方、QuDedup およびバージョン管理を共におこなわない場合は、バックアップの管理オブジェクトこそ追加されていますが、基本的にはローカルフォルダおよびファイルに対応して、S3上のフォルダ、オブジェクトが作成されていました。
このため、この方式でバックアップを保存した場合は、直接S3のオブジェクトを取得することで、ファイル単位でデータを取り出すことも可能です。ただし、S3上の最終更新日時はバックアップ時の日時となるため、取得したファイルの更新日時が元のファイルの情報を反映していないという状態になるので注意が必要です。
なお、念のために書いておきますが、QNAP の HBS3 の復元機能を使って復元すれば、この場合も正しい最終更新日時で復元することができます。
QuDedup Extract Tool による復元
あと、一つ気になったのが、S3 上で qdff フォルダを利用した形式で保存された場合、 QNAP の NAS がないとデータを一切取り出すことができないのか?という点です。 まあ、 QNAP の NAS に悪い印象は持っていないのですが、既存の QNAP の NAS が破損した場合などに、他社の NAS に乗り換えないとも言えません(何らかの事情でQNAP製品が入手困難になっていることなども想定されます)。その時、バックアップからデータが復元するすべがないとなるとかなり困ってしまいます。
実は、 QuDedup の紹介をよく読むと、 NAS がなくても、 OS 上にインストールするツール( QuDedup Extract Tool )があり、それを使うとバックアップからデータを取り出すことができるそうです。
これがあれば、最悪何とかなりそうですね。これも試してみます。
qdff フォルダの取得
テスト用に、S3 から qdff フォルダ一式をダウンロードしておきます。
mor@DESKTOP-H6IEJF9:/mnt/c/Users/mor$ aws --profile xxxxxxxxxx s3 cp --recursive s3://my_bucket_prefix.backup.nas/tempBackup.qdff/ ./test/
(WSLで操作しています)
インストール
ツールのバイナリは、Windows、 Mac、 Ubuntu があるので、使いたいバイナリを選択します(今回はWindows)。 ダウンロードしたファイルをダブルクリックして、インストーラを起動し、画面指示に従ってインストールします。
復元
早速ツールを起動します(UIは残念ながら、英語と中国語のみのようです)。
初回起動時は設定画面が表示されますが、とりあえずはデフォルトのままとしておきます。起動すると、下記のような画面になるので、
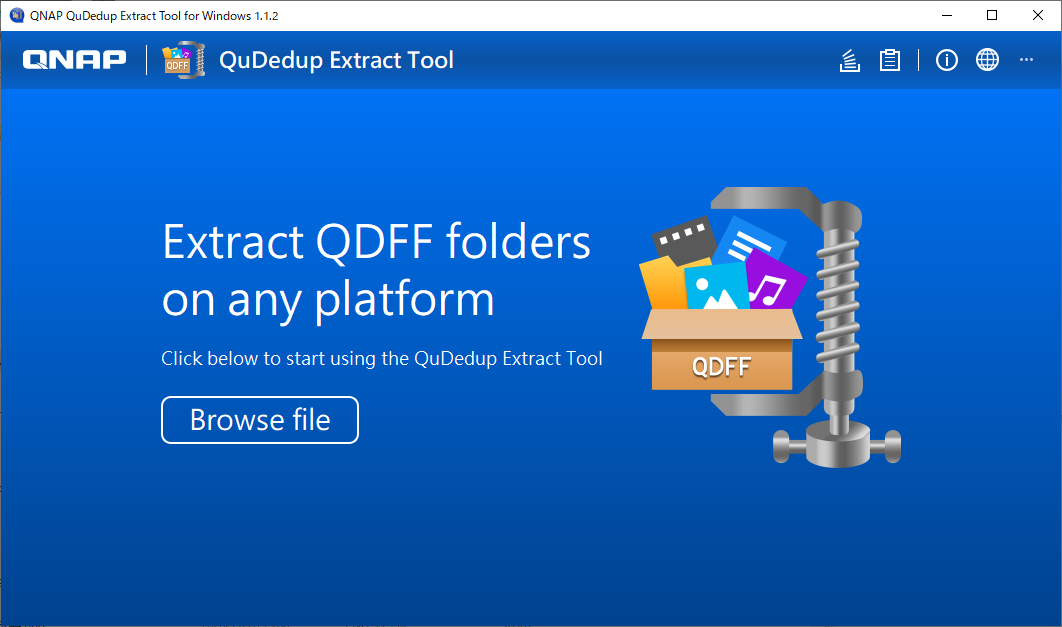
中央の『Browse file』をクリックして、qdff フォルダを指定します。
qdffフォルダを指定すると、下記のようにフォルダ選択画面が出てきます。

このツールでは、フォルダ単位またはファイル単位で復元することができます。
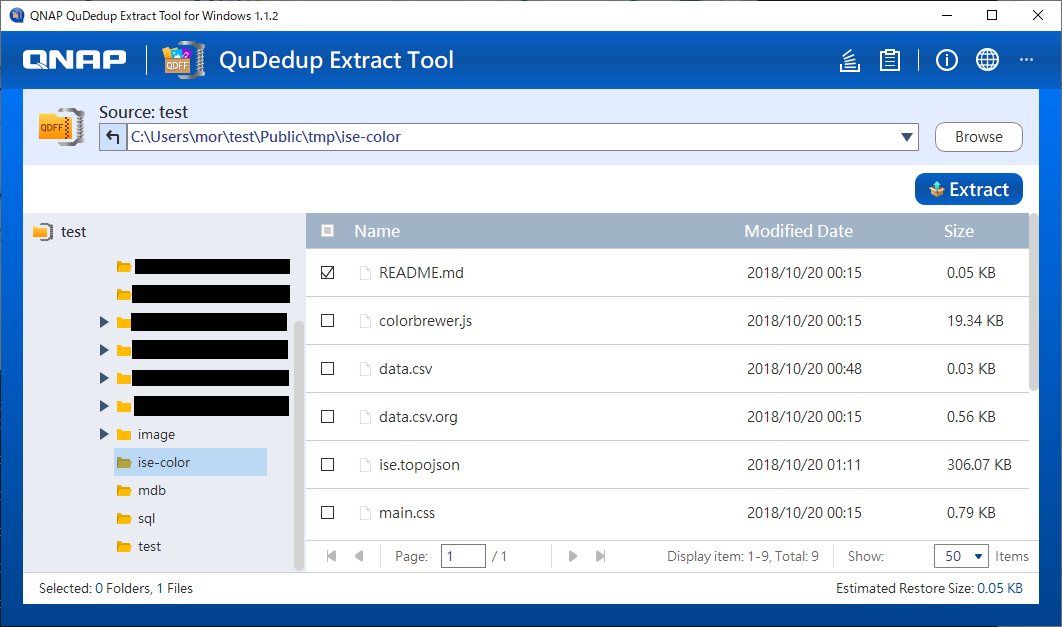
復元したいものにチェックをつけて、『Extract』ボタンを押すと、

のように予想される復元容量に関する警告が表示されます。 『OK』を押すと、保存先を選択するダイアログが表示されるので、フォルダを指定します。
すると、ファイルがぶつかった場合の処理が尋ねられるので、
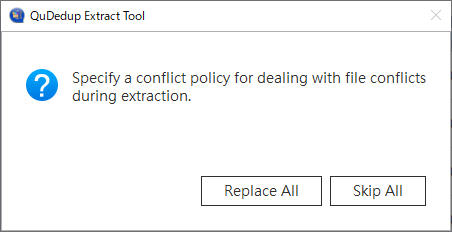
replace か skip かを選択します。 復元が完了したら、下記のように結果が表示されます。
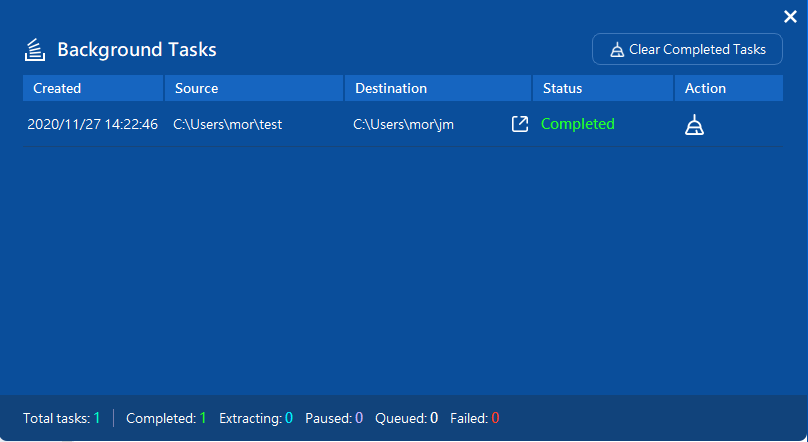
復元先のフォルダを見ると問題なくファイルが復元されていました。
なお、QuDedup なしの場合でも、バージョン管理がありであれば、このツールで復元することができました。
一方、QuDedupもバージョン管理もない場合は、このツールでは復元することができません。一応バックアップフォルダ全体をS3からダウンロードして、このツールで読み込ませると、
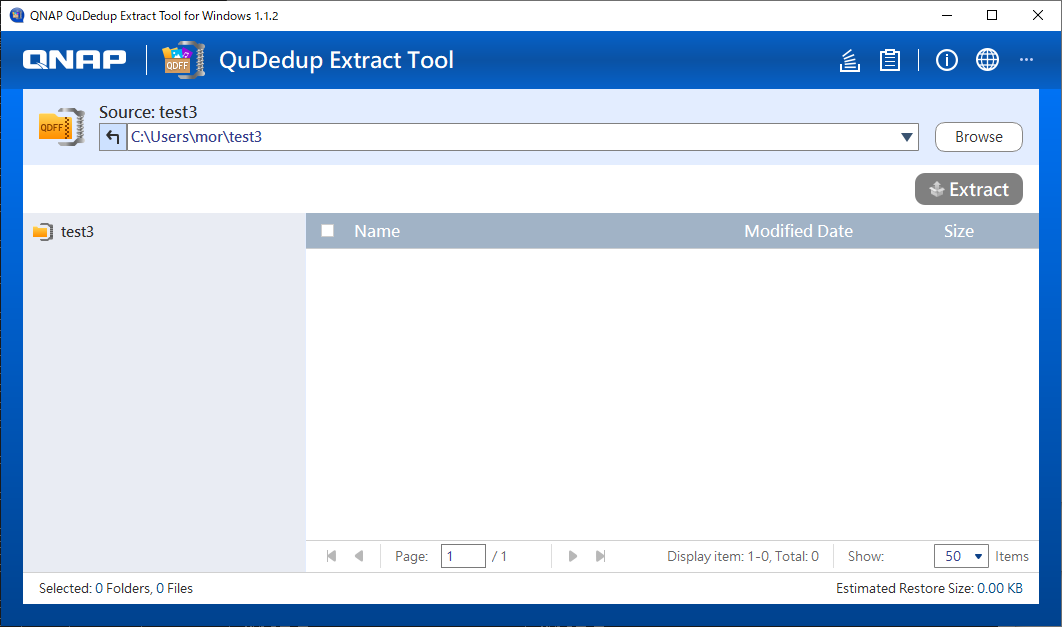
のようにエラーにはなりませんが、ファイル・フォルダが表示されません。
要は、上述したように、バックアップ時に qdff フォルダが作成される場合は処理できて、その他は処理対象外になるということなんでしょうね。
雑感
というわけで、この QuDedup Extract Tool さえあれば、QNAP NAS がなくてもデータの復元ができそうです。もっとも、TB 単位などの巨大なバックアップを扱う場合は現実的ではないかもしれません。
ということで、バックアップデータのサイズや目的次第になりますが、qdff フォルダをローカルにさえ持ってこれれば、QNAP NAS がなくても取り出すことができるので、S3 から直接ファイルを復元する必要性を感じて、QuDedup やバージョン管理をわざわざ無効にしてバックアップを行う必要性はそんなになさそうですね。
バックアップジョブの削除
最後に、バックアップジョブを削除した場合、S3上のデータがどうなるか確認しておきます。
試してみると、 QNAP の HBS3 上からバックアップジョブを削除しても、S3の当該バケットからはバックアップデータは削除されませんでした。 まあ、バックアップデータなので、積極的に削除しないんでしょうね、きっと。
ですが、クラウド上のストレージの容量が気になるような場合は、不要なバックアップデータが残らないように手作業で消す必要があるので、その点だけ覚えておく必要がありそうです。
まとめ
クラウドバックアップ、便利ですね。なんで今まで放っておいたんだろうか?という気分です。 あとはクラウド上のストレージ容量と料金が気になるところですが、当面はデータ量も大したことないので大丈夫でしょう。
これで、データをクラウド上に残すようにでき、一安心です。よかった、よかった。