こちらの記事
の続きです。ここまでで一通りの基本的な設定はできました。ですが、やっかいなのは LINE です。
最初は自分が LINE 使っている程度(メッセージアプリの一つ)の認識だったので、子どもに聞かれたときも『 LINE 使っていいよー』、と伝えていたのですが、アプリ内ブラウザについて調べていた時に、いろいろと気になる機能があることがわかってきました。特に、
- LINE VOOM
- LINE ニュース
- オープンチャット
あたりを使うと、実質的に制限なしにいろんなコンテンツや他人に触れることができてしまいます。
VOOM というのはいわゆるショート動画のサービスっぽいので、きっと使いたいというと思うんだけど、制限なしはもうちょっと待ってほしいかな。
オープンチャットもオープンというだけあって、いろんなことが起こりえるのが容易に想像できます。
ニュースは見せてあげたい感じもしますが、自分自身が使ってないので、いったんは様子見にさせてもらいます。
にしても、 LINE もアプリ内のこの手のコンテンツの年齢制限とかにもうちょっと取り組んでもらえないもんでしょうかね?まあ、 LINE の言い分としては、サービスは 12歳からにしているので、使う側で何とかしてよ、ということなんでしょうが、実際問題これだけ普及しているのだから、もうちょっと真剣に LINE 内でのアレンタルコントロール機能について検討してほしいものです。
ここで愚痴っても仕方ないので、 LINE を使ううえで、これらのアクセスをどうするかの対策を考えます。
LINE の基本設定
まずは、 LINE 自体の設定を見直しておきます。あちこち変更したのですが、主に下記を参考にしました。
子どもにLINEを使わせる前に必須の制限設定8選 VOOM対策や代替アプリ | キッズスマホ選び ママペディア
VOOM 関係はこんな感じです。
- 『ホーム』 -> 『設定』(歯車) -> 『LINE VOOM』 -> 『LINE VOOM 通知』で『すべての通知』をオフ
- 『LINE VOOM』 -> 『フォロー設定』->『フォローを許可』をオフ
- 『ホーム』 -> 『設定』(歯車) -> 『写真と動画』-> 『動画自動再生』を『自動再生しない』に設定
LINE の友達関係はこんな感じです。
- 『友だち自動追加』を無効
- 『友だちへの追加を許可』を無効
- LINE ID は作成しない
その他、主にプライバシー関係の設定はこんな感じにしました。
- 『ホーム』 -> 『設定』(歯車) -> 『プライバシー管理』-> 『メッセージ受信拒否』を有効
- 『プライバシー管理』-> 『アプリからの情報アクセス』を『拒否』に設定
- 『プライバシー管理』-> 『情報の提供』 -> 『LINE 通知メッセージ』の『LINE 通知メッセージを受信』を無効
子どもが自分で設定を変更できる点はありますが、親が提供する初期設定としてはこんな感じにしました。
LINE VOOM
i-フィルターでアプリ内ブラウザによるアクセスは抑えました。でも、 LINE VOOM は抑えられません。どうしたものか?子どもに使わないでと伝える方法でもいいのですが、何か対策はないものかと思って調べてみると、先人がやってくれていました。
なるほど。スマホのアプリ自動化のツールを利用して LINE VOOM を起動できないようにするというものですか。早速試してみました。
MacroDroid による LINE VOOM 起動抑制
基本的にやったことは、上記の記事の通りですが、若干変更しています。順を追ってまとめておきます。
MacroDroid のインストール
まずは、 MacroDroid をインストールします。以前は、無料のアプリだったようなんですが、下記の記事にあるように、無料で使えるのは期間限定のアプリになったようです。
価格.com - 『MacroDroidが期間限定有料アプリに』 Androidアプリのクチコミ掲示板
広告を見ると無料期間が延長されるようなんですが、子どものスマホ用にそんなことしたら本末転倒なんで、ここはいさぎよくお金を払っておきます。幸いなことに月額課金じゃないので、最初だけですしね。
ちなみに、 MacroDroid のインストールと設定のタイミングが、 Google ファミリーリンク設定後でした。このため、 Google Play からのアプリのインストールが『すべてのコンテンツを承認』になっていたので、 MacroDroid アプリ側でプロ版にアップグレードしようとしても、失敗してしまいました。なので、一時的に承認をなしにして、プロ版へのアップグレードを行いました。作業がが完了したら、再度制限を有効にしました。
マクロの作成
MacroDroid でマクロを作成します。まずは、ホーム画面の下部にある『マクロ』をタップします(以下の画面は無料期間内のものになるため、画面下部にその旨のメッセージが出てます)。
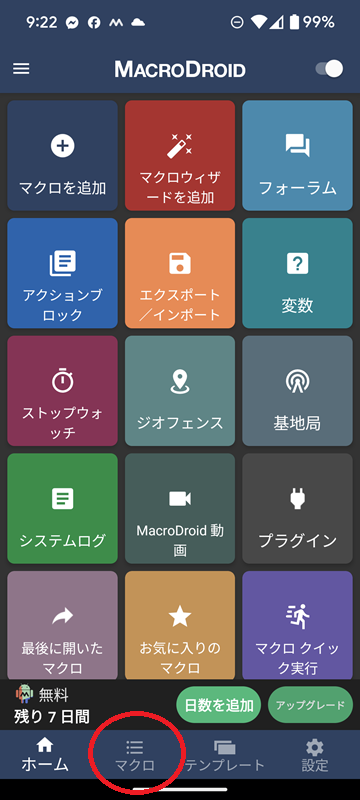
もちろん画面内の『マクロを追加』ボタンを押してもOKです。次に、マクロが起動するきっかけとなる『トリガー』を設定します。
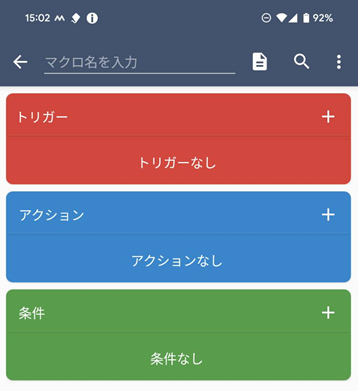
『トリガー』の右上の『+』ボタンをタップすると
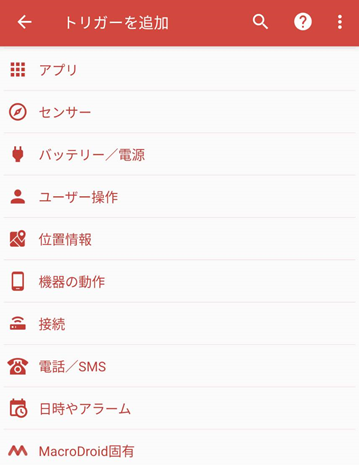
このようなトリガー種類の選択画面が表示されるので、この中の『アプリ』を選択します。
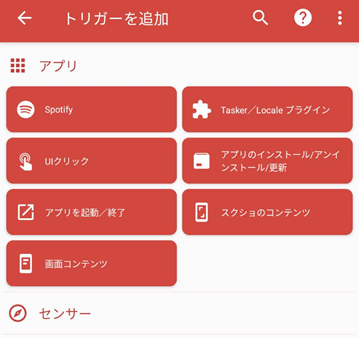
ここで、『画面コンテンツ』を選択します。設定内容の『アプリ』は『すべてのアプリ』ではなく、 LINE を選択します。
そして、表示される画面コンテンツとして
- コンテンツID が『content_profile_follow』であるとき
とします。
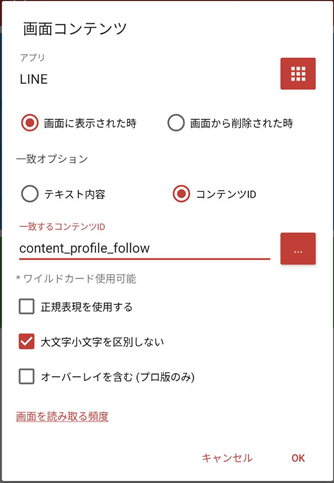
これは、前述の記事にあるように、LINE VOOM 画面には必ず『フォロー』が表示されるので、それを利用してトリガーにしていることになります(テキストではなくコンテンツID にしているのは前述の記事に倣っています)。
次に『アクション』を設定します。本当は、『アプリ』にある『アプリを強制停止』を使いたいところなんですが、

アプリを停止させるのは root 化する必要があるようです。子どものスマホにそんなことはできないので、どうしようかと思って調べると、
【RPA】【MacroDroid】Fish and Tips ルートをとらなくてもアプリは終了できるよ - 駅前散策ブログ@かわさき HOT
というのを見つけました。なるほど、いったんホーム画面を表示させて、その後バックグラウンドアプリを終了させるという方法が取れるようです。
早速やってみます。まず『アクション』をタップします。次に、『機器の操作や動作』をタップします。次に『ホーム画面を表示』をタップします。
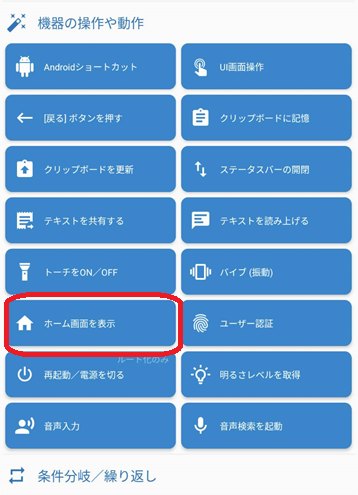
これで、アクションに『ホーム画面を表示』が追加されました。
次のバックグラウンドアプリを終了させるまえに、少し待機します。待機は『マクロ』を選択し、『次のアクション実行前に待機』をタップします。
待機時間を指定するダイアログが表示されるので、5秒とし、『アラーム機能を使う』はチェックを外しておきます。
最後に、3つ目のアクションとして、『アプリ』から『バックグラウンド動作アプリを強制終了』を選択します。アプリの選択ダイアログが表示されるので、LINEを選択します。
最後に、マクロ名を追加して保存します。プロ版にアップグレード前なら、この時に広告が表示されますので、閉じるなり広告を見るなり、いいようにしてください。
保存ができたら、マクロ一覧画面が表示されます。下記のように、マクロが有効になっていれば、もう動いています。
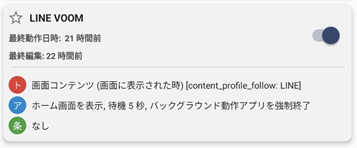
なお、 MacroDroid のマクロの各種トリガーやアクションの内容については、下記の記事を参考にさせていただきました。
マクロを試す
では、早速試してみます。
- LINEを起動します
- LINE VOOM をタップします
- ホーム画面が表示されます
なんですが、残念ながら、アプリを終了させることはできないようです。前述の MacroDroid の説明記事をよく読むと、『バックグラウンドアプリを強制終了』は、
【注意】 このアクションは、バックグラウンドで現在実行中のアプリではなく、非活動のバックグラウンド処理を強制終了します。
とのことです。なので、バックグラウンドに回ったばかりの LINE を停止することはできないっぽいですね。
とはいえ、 LINE VOOM を使うことができなくなるのは同じなので、とりあえずこれでも OK としました。
あと、一度 VOOM を表示してホーム画面を表示した後、再度、 LINE をフォアグラウンドに持ってきたとき、前と同じく VOOM の画面が表示されるので、間髪入れずまた落ちる時があります。このような場合は、一度タスクを落としてから、 LINE を起動する必要があります。
また、たまに、VOOM で落ちた後 LINE を起動すると、トーク画面でも落ちる場合があります。これは、完全な推測なんですが、 VOOM の画面の上にトークの画面が重なっているような状態ではないかと推測しています。実際、 LINE を停止させてから再度トークのみを表示されると問題なく動作しています。
まあ、こんな感じで、若干使い勝手が悪くなりますが、基本的には VOOM を使ってほしくないので、ここは割り切って、落ちたときは、いったん LINE を終了させてから、また起動してね、としておきます。
LINE ニュース
ネットを調べると、 LINE ニュースを非表示するには、設定により通話に切り替えるというのがあるようです。まずはそれをやっておきます。
- 『ホーム』 -> 『設定』 -> 『通話』 -> 『通話/ニュースタブ表示』-> 『ニュース』を『通話』に変更
そのうえで、 LINE VOOM と同様に、 MacroDroid で画面を落とすようにします。ただし、トリガーとしては、
- テキスト内容が『主要ニュース』であるとき
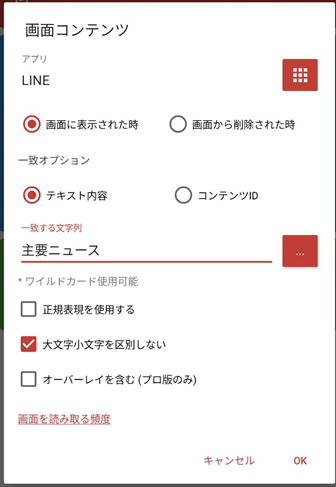
としておきます。
オープンチャット
LINE VOOM や LINE ニュースと同様に、 MacroDroid で画面を落とすようにします。ただし、トリガーとしては、オープンチャットを開いた画面にある文字列を使い、
- テキスト内容が『LINE オープンチャット』であるとき
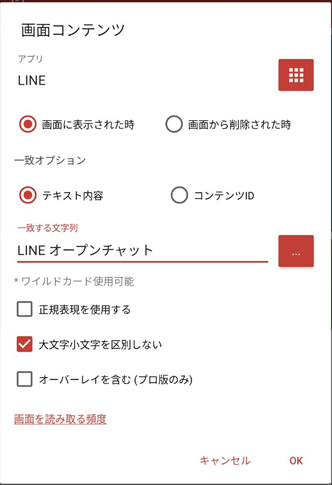
としておきます。
あと、オープンチャットの制限の方法として、下記の記事のように、特定の URL へのアクセスを制限するという方法もあるようです。
ASCII.jp:子どもが不特定多数と交流できるLINEのオープンチャットを制限する方法
なので、こちらも i-フィルターと Google ファミリーリンクの Chrome の設定に追加して、『 square-api.line.me 』をブロックするようにしておきます。
その他
他に LINE を使ううえで、気になる点としては、
- LINE ウォレット
- LINE ポイントクラブ
- トークの『みんなでみる』機能(特に、 YouTube)
あたりの制限をどうするかが気になる点です。
制限しようかとも思ったのですが、
- 子どもとの約束事として『課金などはしない』としている
- スマホで許可されたコンテンツの内容であれば、時間の使い方までは管理したくない
というのがあって、一旦保留にすることにしました。ポイントを貯めようとした際に、アクセスする広告や漫画、ゲームの内容が気になるといえば気になるけど、そのあたりは様子見にします。そもそもスマホの時間そのものが制限されているのでどこまでこれらに価値を見出すかもわかりませんしね。
3つ目のみんなで見る機能も、たぶん YouTube のレーティング制限はかからないだろうから気になるといえば気になりますが、
- 複数の友達同士で見ることになる点
- 家ではリビングでのみスマホを使ってよい
という点から、こちらも制限せずに様子見としました(外で見ることは可能ですが時間的にも限定的になるので)。
にしても、 LINE 本当に悩ましいです。
(参考)AdGuard for Android
なお、上記では MacroDroid を使いましたが、 AdGuard for Android を使っても、いろいろと制限をかけることもできるようです。 が、こちらのアプリは Google Play での公開ではなく、配布元からのダウンロードになります(Google Play で公開されているのは一部機能のみのバージョン)。ということで、ちょっと躊躇してしまい試しませんでした。
勇気のある方は、こちらを試してもいいかもしれませんね。
まとめ
まあ、子どもも小学生高学年なんで、いろいろと設定するのもここ数年のことだとは思います。それに、いろいろとやりましたけど、どうせ抜け穴は探し出してくるんでしょうから、そこまで神経質になることもないかなと思います。とはいえ、昨今何があるかわからないから、矛盾するようですがちょっと慎重にもなります。
今回、自分でこの記事まとめてみて、若干やりすぎかな?と思うところもあるのですが、最初は厳しめにしておいて、あとは子どもからのリクエストや普段の子どもの言動をみながら、徐々に緩めていこうかなと思います。
子どもがうまくスマホと付き合えるようになることを切に願います。