はてなブログに移行してくる前から、Syntaxhiglighter を使っていたんですが、どうもここしばらく開発が止まっているようです。
一応、こちらの記事に書いたように v4 に対応させて使っていたんですが、最近手を出している新しめの言語、 dart (flutter で利用) とかに対応していないのが、気になってきました。 それと、スマホには対応していないんですよねー。
そんなことが重なったので、そろそろ替え時かな?と思うようになりました。 というわけで、 SyntaxHighlighter から はてなブログが提供している markdown によるコードハイライトに切り替えようと思い立ちました。
ただ、既存の記事が多数あるので手作業は嫌です。幸い、はてなブログでは、API経由で投稿・編集ができるので、それを使って、らくちんで対応したいと思います。
というわけで、移行時に行った作業のメモをまとめておきます。
API について
まず、はてなのAPIでできることを調べてみます。
はてなブログAtomPub - Hatena Developer Center
エントリー一覧の取得、個別の記事の取得、新規投稿およびアップデートと一通りのことができますね。
wget を使ってエントリー一覧をとってみます。認証は Basic 認証です。
mor@DESKTOP-H6IEJF9:~/work/hatena$ wget --user=はてなID --password=APIキー https://blog.hatena.ne.jp/はてなID/ブログID/atom/entry -O test.xml Will not apply HSTS. The HSTS database must be a regular and non-world-writable file. ERROR: could not open HSTS store at '/home/mor/.wget-hsts'. HSTS will be disabled. --2020-12-23 10:15:42-- https://blog.hatena.ne.jp/はてなID/ブログID/atom/entry blog.hatena.ne.jp (blog.hatena.ne.jp) をDNSに問いあわせています... 13.115.18.61, 13.230.115.161 blog.hatena.ne.jp (blog.hatena.ne.jp)|13.115.18.61|:443 に接続しています... 接続しました。 HTTP による接続要求を送信しました、応答を待っています... 401 Unauthorized 選択された認証形式: Basic realm="Hatena Blog" blog.hatena.ne.jp:443 への接続を再利用します。 HTTP による接続要求を送信しました、応答を待っています... 200 OK 長さ: 特定できません [application/atom+xml] `test.xml' に保存中 test.xml [ <=> ] 187.44K --.-KB/s 時間 0.04s 2020-12-23 10:15:42 (4.57 MB/s) - `test.xml' へ保存終了 [191940] mor@DESKTOP-H6IEJF9:~/work/hatena$
こんな感じで XML が返ってきました。
<?xml version="1.0" encoding="utf-8"?> <feed xmlns="http://www.w3.org/2005/Atom" xmlns:app="http://www.w3.org/2007/app"> <link rel="first" href="https://blog.hatena.ne.jp/はてなID/ブログID/atom/entry" /> <link rel="next" href="https://blog.hatena.ne.jp/はてなID/ブログID/atom/entry?page=xxxxxxxxxxx" /> <title>プログラマーのメモ書き</title> <subtitle>伊勢在住のプログラマーが気になることを気ままにメモったブログです</subtitle> <link rel="alternate" href="https://blog.mori-soft.com/"/> <updated>2020-12-17T17:20:51+09:00</updated> <author> <name>junichim</name> </author> <generator uri="https://blog.hatena.ne.jp/" version="4d0fe3f3cd3a840afb05e29c86af788f">Hatena::Blog</generator> <id>hatenablog://blog/yyyyyyyyyyyyyyyyyyyyyyy</id> <entry> <id>tag:blog.hatena.ne.jp,2013:blog-はてなID-xxxxxxxxxxxxxxxxxxxxxx-yyyyyyyyyyyyyy</id> <link rel="edit" href="https://blog.hatena.ne.jp/はてなID/ブログID/atom/entry/エントリーID"/> <link rel="alternate" type="text/html" href="https://blog.mori-soft.com/entry/2020/12/23/002700"/> <author><name>junichim</name></author> <title>はてなブログのコードハイライトを SyntaxHighlighter から はてなの markdown に変更</title> <updated>2020-12-21T16:02:21+09:00</updated> <published>2020-12-18T10:55:34+09:00</published> <app:edited>2020-12-23T00:27:00+09:00</app:edited> <summary type="text">はてなブログに移行してくる前から、Syntaxhiglighter を使っていたんですが、どうもここしばらく開発が止まっているようです。 github.com 一応、こちらの記事に書いたように v4 に対応させて使っていたんですが、>最近手を出している新しめの言語、 flutter…</summary> <content type="text/x-markdown">はてなブログに移行してくる前から、Syntaxhiglighter を使っていたんですが、どうもここしばらく開発が止まっているようです。 [https://github.com/syntaxhighlighter/syntaxhighlighter:embed:cite] 一応、[こちらの記事](https://blog.mori-soft.com/entry/2018/01/31/224619)に書いたように v4 に対応させて使っていたんですが、最近手を出している新しめの言語、 flutter (dart) とかに対応していないのが、気になってきました。 それと、スマホでみると、シンタックスハイライトがうまく機能していません。
これだけではちょっとわかりにくいですが、エントリーIDの一覧が返ってくるかと思いきや、一度に複数件(これ試したときには10件、ドキュメント上は7件)の記事が完全な形で取得されています。
で、次の一覧を得るためには、取得したドキュメント内のlink要素(rel属性がnextのやつ)のURLを呼ぶという形になるようです。 pageパラメータの求め方がわからないので、順番にコレクションを取得して、次のURLを呼び、得られたコレクションにある次のURLを呼び・・・という形を用いて、すべてのエントリーを得ることができるようです。
page パラメータをダイレクトに求められれば、もうちょっと楽な気がします。
個別の記事については、entry タグに含まれている link タグから、エントリーIDを切り出せば、アップデートに使えそうです。
こういう処理は Python でやると楽そうですね。なかなか本格的に Python を使う機会もないので、手元の書籍を見ながらボチボチ組んでみます。
Python スクリプトの作成
まず、コードを書く前に、 SyntaxHighlighter での言語指定と はてなブログの markdown の言語指定の対応を調べる必要があります。
とはいっても、すべての言語の対応表を作るなんて、ばからしいので、今回はこういう風に対応することにしました。
- 既存の SyntaxHighlighter の言語指定を抜き出し一覧にする
- はてなブログの markdown で対応している言語名との対応表を作る
- できた対応表を用いて、 SyntaxHighlighter の記述を markdown に変換する
また、全体の処理の流れとしては、
- コレクションAPI にてエントリー一覧(10件分)を取得
- 各エントリーについて以下を実施
- XML をパース
- SyntaxHighlighter の記述があるか判定
- なければ、次のエントリーへ
- あれば、必要な処理を行う(SyntaxHighlighter で指定されている言語の取得や記述の変換)
という感じでしょうか。
API からデータを取得
Python で http 経由で何かを取得するのは urllib が楽なようです。また、はてなのAPIは認証が必要です。今回は、 Basic 認証にします。
下記記事などを参考に、 urllib から Basic 認証で API をたたいて、XML を取得します。
最初に試したとき、APIの最後にスラッシュが付いていたのに気づかず、404 が返ってきてしまい、なんでだ?となってしまいました。お気を付けください。
XML の解析
はてなのAPI からは XML が返ってきます。 Python で XML を操るには、 ElementTree を使うのが王道っぽいですね。
- xml.etree.ElementTree --- ElementTree XML API — Python 3.9.1 ドキュメント
- 【Python入門】ElementTreeを使ってXMLの解析に挑戦しよう! | 侍エンジニア塾ブログ(Samurai Blog) - プログラミング入門者向けサイト
まずは、パースして、個別のエントリーを取得すればよさそうです。
ただ、はてなの API で返ってくる XML は名前空間が指定されているので、そこだけ、工夫してやります。
XML の名前空間はこんな感じです。
<?xml version="1.0" encoding="utf-8"?> <feed xmlns="http://www.w3.org/2005/Atom" xmlns:app="http://www.w3.org/2007/app">
デフォルト名前空間も含めて、下記のような名前空間の辞書を作ります。
# ドキュメント XML の namespace ns = {'def': 'http://www.w3.org/2005/Atom', 'app': 'http://www.w3.org/2007/app'}
ElementTree の find などを使うときは、この名前空間を指定してやります。例えば、 entry タグをとりたければ、
self.__entries = root.findall('def:entry', ns)
のようにデフォルト名前空間も明示的に指定してやります。
これで、名前空間付きでタグとかが取れるようになりました。
(参考)
エントリーの取得処理
ここまでをまとめて、このデータ取得部分を含めたクラスを作って、イテレータでアクセスできるようにしました。
こんな感じですね。
# ドキュメント XML の namespace ns = {'def': 'http://www.w3.org/2005/Atom', 'app': 'http://www.w3.org/2007/app'} class HatenaEntries(): ''' はてなブログのエントリー(記事)を取得し、イテレータで扱うためのクラス ''' def __init__(self): self.__isFirst = True self.__count = 0 self.__index = None self.__entries = None def __iter__(self): return self def __next__(self): # 最初の呼び出し if self.__isFirst: self.__isFirst = False url = self.__getFirstpageUrl() self.__getCollectionFromHatena(url) if self.__entries is not None and self.__index == len(self.__entries) - 1: # 次のコレクションを設定 self.__getCollectionFromHatena(self.__nextUrl) if self.__entries is None: raise StopIteration() self.__index += 1 return self.__entries[self.__index] def __getCollectionFromHatena(self, url): if url is None: self.__entries = None self.__index = None self.__nextUrl = None return root = self.__getEntryCollection(url) self.__entries = root.findall('def:entry', ns) if self.__entries is None: self.__index = None else: self.__index = -1 self.__count += len(self.__entries) self.__nextUrl = self.__getNextpageUrl(root) def __getFirstpageUrl(self): url = os.path.join(BASEURL, ENTRY_PATH) return url def __getNextpageUrl(self, root): for child in root.findall('def:link', ns): if child.get('rel') == 'next': return child.get('href') return None def __getEntryCollection(self, url): basic = base64.b64encode('{}:{}'.format(USER,PASSWORD).encode('utf-8')) headers={"Authorization": "Basic " + basic.decode('utf-8')} print("request url: {}".format(url)) req = urllib.request.Request(url, headers=headers) try: with urllib.request.urlopen(req) as res: data = res.read() except urllib.error.HTTPError as err: print("exception occured to get entry collection"); print(err) return None except urllib.error.URLError as err: print("failed connection to server"); print(err) return None # XML に変換 root = ET.fromstring(data) return root def getCurrentArticles(self): ''' 現在までに読み込んだエントリー数 ''' return self.__count
SyntaxHighlighter の記述の検出と言語の抽出
エントリーが取れるようになったので、次は正規表現で対象があるかをチェックします。
SyntaxHighlighter は
<pre class="brush: 言語名">
という記述をするのが基本なのですが、過去の経緯もあり、いくつかの表記パターンがありました。
<pre class="brush: 言語名"> <pre class="brush: 言語名" data-unlink=""> <pre class="brush: 言語名", data-unlink=""> <pre class="brush: 言語名;"> <pre class='brush: 言語名'>
これらをカバーするような正規表現を作ってみます。
pattern = re.compile('(<\s*pre\s+class\s*=\s*(?P<quot>[\"\']?)\s*brush\s*:\s*([\d\w]+)\s*;?\s*(?P=quot)\s*,?\s*(?:data-unlink\s*=\s*(?:\"\"|\'\'))?\s*>)(.+?)(</\s*pre\s*>)', re.MULTILINE | re.DOTALL)
コード部分が複数行にわたるので、 MULTILINE と DOTALL を指定した処理にしています。 また、開始preタグ、言語名、コード本体、終了preタグをグループにして取得できるようにしています。 あとは、空白の有無とかクォーテーションの違いとか、各記号・data-unlink表記の有無に対応できるように作ってみました。
とはいえ、いきなりこの正規表現を作るのはたいへんでしたので、下記サイトなどで、チェックしながら作りました。
言語一覧の取得
上記で取得できるようになった各エントリーに対して、こんな感じでチェックしてやります。
import hatena_entries as HE # 記事情報の取得 # isLang, true: 言語一覧, false: 記事タイトル一覧 def listup(entry, isLang): global num_convert content = entry.find('def:content', HE.ns) title = entry.find('def:title', HE.ns) resultSet = set() # content に syntaxhighlighter の記述 があるか if content is not None and content.text is not None: m = pattern.findall(content.text) if len(m) > 0: num_convert += 1 if isLang: for v in m: resultSet.add(v[2]) # #3 lang else: resultSet.add(title.text) return resultSet
set(集合)を利用して、言語名の重複を除いてやります。
取得した言語名一覧と対応表
最終的に作成した言語名一覧と対応表は下記のような辞書にまとめて、変換処理で使うようにしました。
# 言語指定の変換一覧 # key: SyntaxHighlighter # val: はてなブログ markdown lang= { "actionscript3": "actionscript", "bash": "sh", "cpp": "cpp", "dart": "dart", "html": "html", "java": "java", "javascript": "javascript", "js": "javascript", "json": "javascript", "php": "php", "python": "python", "scala": "scala", "sql": "sql", "text": "", # text には単なるコードブロックを対応させる "vb": "vb", "xml": "xml", "yaml": "yaml", }
SyntaxHighlighter の記述を markdown へ変換
SyntaxHighlighter のタグさえ見つけられれば、変換はさほど難しくありません。
こんな感じで、変換関数を定義して変換します。
def replacer(matchObj): nl1 = "" if matchObj.group(4)[0] == "\n" else "\n" nl2 = "" if matchObj.group(4)[-1] == "\n" else "\n" # 問題再現 #nl1 = "" #nl2 = "" return "```" + codeLang.lang[matchObj.group(3)] + nl1 + matchObj.group(4) + nl2 + "```" def getConvertedContent(content_text): return re.sub(pattern, replacer, content_text)
実は、上記は正しく動作するのですが、当初は下記のように pre タグを置き換えるだけにしてしまいました。
def replacer(matchObj): return "```" + lang[matchObj.group(3)] + matchObj.group(4) + "```"
すると、開始preタグの後ろに改行なしでコード本体が書かれている場合に、言語名とコード本体がつながってしまうという事態になってしまいます。
この記述で問題ないと思い込んでしまったため、本番のブログへも反映してしまい、修正作業が大変になってしまいました。テストは大事ですね。 修正についても、後で述べます。
更新作業
更新はエントリーIDさえ、わかれば簡単です。
def updateEntry(entry_id, entry_xml): ''' エントリーの更新 ''' url = os.path.join(BASEURL, ENTRY_PATH + '/' + entry_id) basic = base64.b64encode('{}:{}'.format(USER,PASSWORD).encode('utf-8')) headers={ "Authorization": "Basic " + basic.decode('utf-8'), "Content-type": "application/xml", } print("request url: {}".format(url)) req = urllib.request.Request(url, headers=headers, data=entry_xml.encode('utf-8'), method='PUT') try: with urllib.request.urlopen(req) as res: data = res.read() except urllib.error.HTTPError as err: print("exception occured for update, entry id: {}".format(entry_id)); print(err) print("continue next entry") except urllib.error.URLError as err: print("failed connection to server"); print(err) print("continue next entry")
なお、当初は method として小文字の put にしていたら、404 が返ってきて、ずいぶんと悩みました。大文字にしたら問題なく更新できました。
実行
スクリプトが完成したので、実行してみます。
まずは言語一覧を取得します。
mor@DESKTOP-H6IEJF9:~/work/hatena$ python3 convert_syntax.py -g (略) num of articles: 326 num of articles to convert: 164 actionscript3 bash cpp dart html java javascript js json php python scala sql text vb xml yaml mor@DESKTOP-H6IEJF9:~/work/hatena$
で得られた結果を Python コードに反映して、変換処理を行います。
mor@DESKTOP-H6IEJF9:~/work/hatena$ python3 convert_syntax.py -c (略) num of articles: 326 num of articles to convert: 164 mor@DESKTOP-H6IEJF9:~$
エラーがでなければ処理完了です。
変換結果
変換した結果は、例えば、こちらの記事のやつだと、
が、

のようになります。
コードハイライトの行番号とかは、カスタマイズ方法がネットにいろいろとあるので、また別途対応したいと思います。
確認と修正
変換した全ての記事を見るわけにはいかないので、いくつかの記事を調べて、取りこぼしや変換ミスがないかチェックします。
正規表現を下記のように変更して
pattern = re.compile('<\s*pre\s+class\s*=\s*[\"\']?\s*brush', re.MULTILINE | re.DOTALL)
タイトル一覧を取得して、差分をチェックします。
増えた記事があったら、変換漏れなので、対応を検討します。今回は、以前のブログよりインポートした記事が、編集モードは markdown なのに、中身は html で記述されていて、そのため、<pre class="brush: " タグを正しく検出できていないというものがありました。なので、これについては、記事そのものを直接修正しました。
言語名とコード本体が結合した問題
で、今回の変換でやらかしたのがこれです。
SyntaxHighliter の記述は html タグでの指定なので改行がなくてもいいことを完全に忘れてました。 仕方ないので、これの修正スクリプトも作りました。正規表現を
pattern_pre = re.compile('^(```)(.+)$', re.MULTILINE) pattern_post = re.compile('^(.+)(```)$', re.MULTILINE)
のように開始部分と終了部分に対応できるように用意します。
変換処理は、開始部分と終了部分で処理を分け、開始部分はトリプルバッククォートに続く文字が、言語辞書に含まれているか文字か否かをチェックして、改行位置を切り替えています。
def pre_replacer(matchObj): langs = set([lng for lng in clang.lang.values() if len(lng) > 0]) for lng in langs: if matchObj.group(2).startswith(lng): pre = matchObj.group(1) + lng content = matchObj.group(2)[len(lng):] if len(content) > 0: return pre + "\n" + content else: return pre return matchObj.group(1) + "\n" + matchObj.group(2) def post_replacer(matchObj): return matchObj.group(1) + "\n" + matchObj.group(2) def fixPreMarkdown(content_text): return re.sub(pattern_pre, pre_replacer, content_text) def fixPostMarkdown(content_text): return re.sub(pattern_post, post_replacer, content_text)
これを、開始タグの修正->終了タグの修正と呼ぶことで、1行で開始タグと終了タグが含まれている場合にも対応できます。
これを実行して、なんとかおおむね修正できました。
html エスケープ文字の修正
SyntaxHighlighter v4 では pre タグで囲まれたコード本体に、 < や > などがあるときは html エスケープしないといけませんでした。 このままだと、markdown方式に変換すると、エスケープした文字がそのまま表示されてしまいます。
これについては、ちょっと面倒ですが、エスケープ文字を含むエントリー一覧を作成して、順次直しました。
これが一番大変でしたね。
br タグの修正
同様に、Syntaxhighlighter のコード本体に br タグが含まれる場合もあります。 これも同様に対象となるエントリー一覧を作成して、順次直しました。
まとめ
まだ、修正による不具合があるかもしれませんが、順次見つけ次第直すことにします。しかし、まあ、意外と修正するところが多くて、予想外に大変でした。変換時に改行コードを入れ忘れるというミスがなければもうちょっと楽だったかな?
似たような作業する方がいれば何かの参考になればと思います。
なお、完成したスクリプト全体は Gist に置いておきますので、ご興味のある方はご自由にお使いください(WTFPL ライセンスです)。
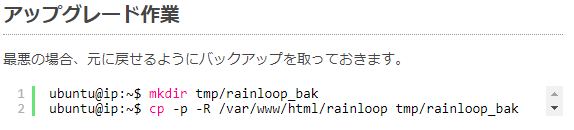
参考:既存のブログのコピーを作成
テスト用に、ブログの記事を一旦エクスポートして、インポートして作業も行いました。
この際、気づいたのですが、インポート後は、編集モードが『見たまま編集』になっています。前述したように、今のブログも別のところからインポートしてきましたが、編集モードはmarkdownです。どういうことだ?仕様が変わったのか?
と思い調べてみると、はてな公式のアナウンスはありませんが、どうも、
- MovableType形式でインポート:みたまま編集モード
- WordPress形式でインポート:markdown
となるようです。下記の事例の記事から推測しました。
ご参考まで。
追記
2020/12/28 追記
SyntaxHighlighter を使わなくなったので、こちらの記事で設定した、cssおよびjsファイルの読み込み設定(はてな側の設定)を削除しました。