こちらの記事に書いたように、メールアカウントの POP3 -> IMAP4 移行に伴い、Rainloop を導入しました。
で、しばらく使って、困ったことがあり、それに伴いいくつか設定を見直したので、メモとして残しておきます。
※ なお、実はこの記事の内容は 2019/11/6 時点での設定で、ブログに投稿しようと思って、大雑把にメモってそのまま忘れ去られていました。先日、下書きが残っているのに気づいたので、改めて公開した次第です。
Rainloop のバージョンは v1.13.0 になります。
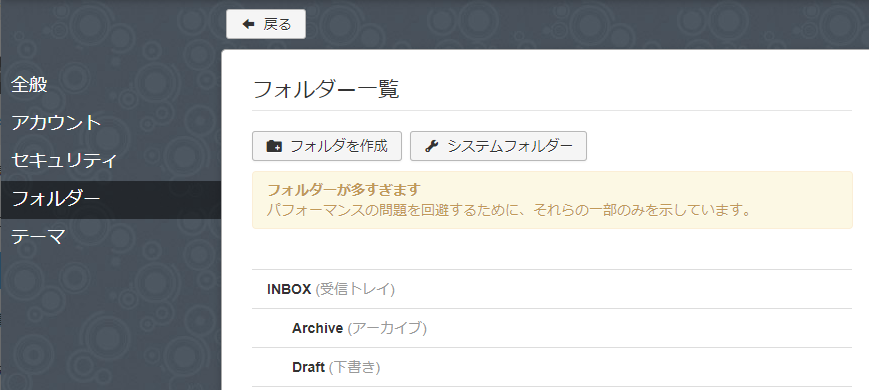
多数のフォルダの処理ができない
フォルダ数が多いと下記のような警告が出て、表示されていないフォルダの操作ができなくなりました。
解決策
下記にあるように application.ini の設定値を変更すれば対応できます。
application.ini は rainloop/data/_data_/_defaul_/configs にあります。
修正前
[labs] ; Experimental settings. Handle with care. ; (中略) imap_folder_list_limit = 200 (後略)
修正後
[labs] ; Experimental settings. Handle with care. ; (中略) imap_folder_list_limit = 300 (後略)
フォルダ数が多い場合は、フォルダ毎の未読がチェックされない
Rainloop ではフォルダ数が 50 (設定ファイルで変更可能です)以上の場合、フォルダ毎の未読数が表示されません(パフォーマンスのため)。
このため、フォルダ数が 50 以上の場合に、未読数の表示を有効にするためには、フォルダ管理画面より、『新しいメッセージをチェックする/しない』を設定する必要があります。ちなみに、デフォルトはシステムフォルダ以外はすべてチェックしないとなっています。
[question] Unread messages · Issue #611 · RainLoop/rainloop-webmail · GitHub
こんな感じで設定していきます。
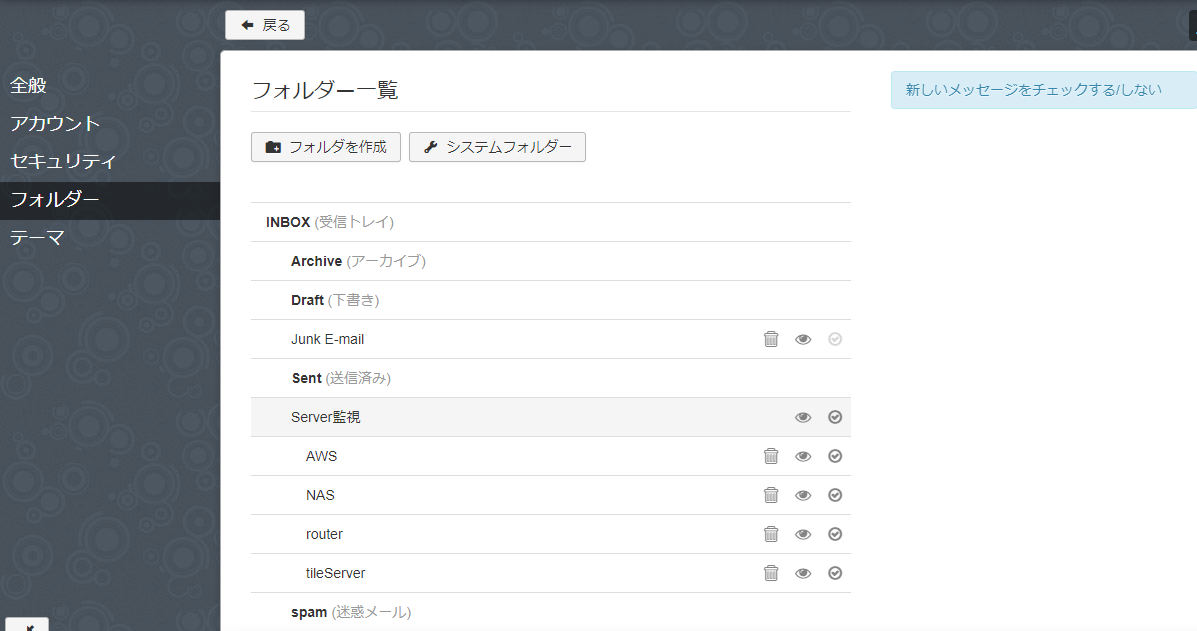
この例の場合だと、 Junk E-mail フォルダは未読数をチェックしませんが、画面内の他のフォルダはチェックになっています。また、太字のフォルダはシステムフォルダです。
なお、すべてのフォルダの未読数を表示する上限は、 application.ini の下記の値を変更すればよいそうです(試してないので、うまくいくかどうかは不明です)。
[labs] ; Experimental settings. Handle with care. ; (中略) folders_spec_limit = 50 (後略)
ログを残すようにする
デフォルトでは、ログは作成されません。ログファイルを残すには、 application.ini の [logs] セクションの設定を変更します。
Activate logging and find logs for {Rainloop in Nextcloud} - PAB's blog
修正前
[logs] ; Enable logging enable = Off ; Logs entire request only if error occured (php requred) write_on_error_only = Off ; Logs entire request only if php error occured write_on_php_error_only = Off (後略)
修正後
[logs] ; Enable logging enable = On ; Logs entire request only if error occured (php requred) write_on_error_only = On ; Logs entire request only if php error occured write_on_php_error_only = On (後略)
先頭の enable = On でログが有効になります。その他の設定は、エラー時のログだけ残したいので設定しました。ほかにも設定オプションがあるので、気になる方はご自分で調べてみてください。
ちなみに、ログファイルの保存先は、 rainloop/data/_data_/_default_/logs フォルダ以下になります。
管理画面のURL
Rainloop の管理画面のURLですが、デフォルトだと、
https://サーバー名/?admin
になっています。でも、デフォルトのままだと不安ですよね?これも変更できます。
admin panel security · Issue #976 · RainLoop/rainloop-webmail · GitHub
変更方法は application.ini の admin_panel_key を変更すればOKです。
修正前
[security] ; Enable CSRF protection (http://en.wikipedia.org/wiki/Cross-site_request_forgery) (中略) ; Access settings admin_panel_key = "admin"
修正後
; Enable CSRF protection (http://en.wikipedia.org/wiki/Cross-site_request_forgery) (中略) ; Access settings admin_panel_key = "my-new-admin-url-query"
変更後は、https://サーバー名/?my-new-admin-url-query でアクセスして表示されるログイン画面から、正しいユーザー名とパスワードを入れることでログインできるようになります。
なお、 https://サーバー名/?admin でもログイン画面が表示されますが、正しいユーザー名とパスワードを入れてもログインできなくなります。
添付ファイルサイズ制限を緩める
デフォルトはこれでした。
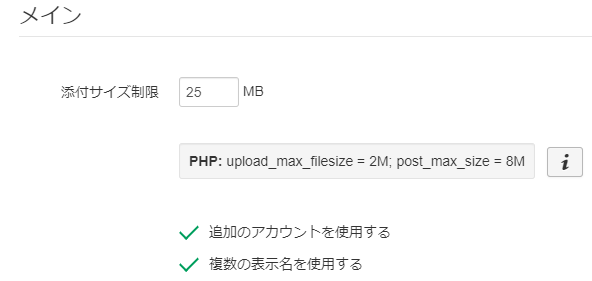
Rainloop 側の制限は 25M でしたが、PHP側でアップロード 2M, ポスト 8M の制限がかかっています。
なので、php側の制限を変更して、大きめのファイルを送信できるようにします。
php.ini を編集する必要があるので、もし、どの php.ini を使っているのか不明であれば、管理画面の『セキュリティ』にある『PHP情報を表示』からphpinfoの情報を見て確認します。
『Loaded Configuration File』をみれば、現在読み込んでいるphp.iniの場所がわかります。
修正前
; Maximum size of POST data that PHP will accept. ; Its value may be 0 to disable the limit. It is ignored if POST data reading ; is disabled through enable_post_data_reading. ; http://php.net/post-max-size post_max_size = 8M および ; Maximum allowed size for uploaded files. ; http://php.net/upload-max-filesize upload_max_filesize = 2M
修正後
; Maximum size of POST data that PHP will accept. ; Its value may be 0 to disable the limit. It is ignored if POST data reading ; is disabled through enable_post_data_reading. ; http://php.net/post-max-size post_max_size = 30M ; Maximum allowed size for uploaded files. ; http://php.net/upload-max-filesize upload_max_filesize = 30M
変更後は、apache を再起動しておきます。
管理画面で確認すると、無事変更されていました。

まとめ
Rainloop フォルダ周りの機能があまりないとか、不満もありますが、一か所でいろんなメールを確認できる環境はなかなか便利です。 IMAP なので、Rainloop 側でのバックアップも設定ファイルを残しておくだけでいいので、そんなに気にしないで済むのもありがたいです。
気になる方は一度試してみるといいかもしれませんよ。